Abstract
We introduce the Generative Frame Sampler (GenS), a novel approach that identifies question-relevant frames from long videos spanning minutes to hours. Given a long video and a user question, GenS effectively searches through the original massive collection of frames to produce a concise selection and enhances the performance of downstream VideoQA Assistants (such as Qwen2-VL, LLaVA-Video, VILA-v1.5, and Aria) by providing fewer but more informative frames. To enable effective frame sampling, we present GenS-Video-150K, a synthetic VideoQA training dataset featuring dense and fine-grained question-relevant frame annotations.
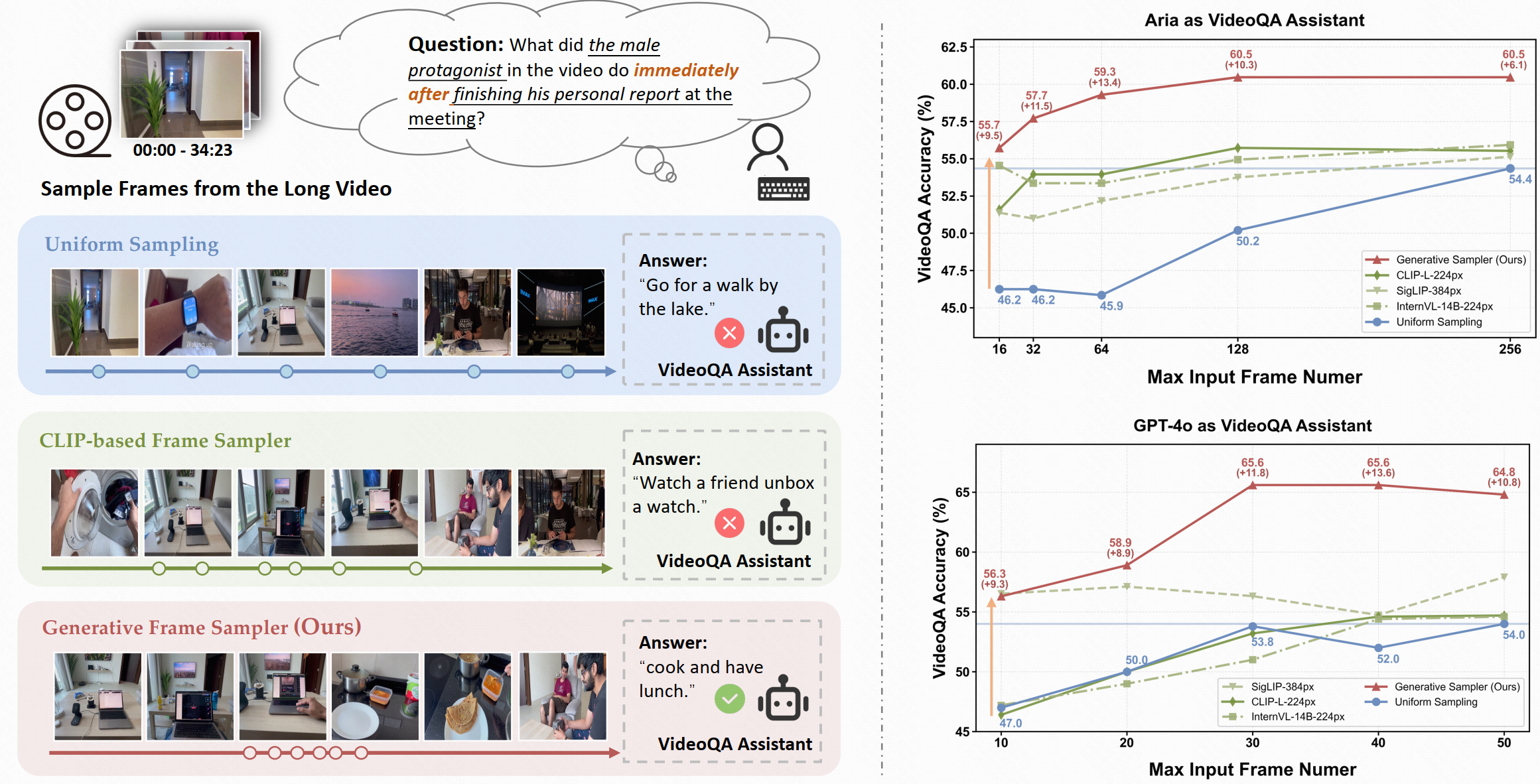
Figure 1: (left) An example of Long VideoQA using different frame samplers. GenS accurately identifies relevant frame sequences based on the user question, further enhancing the performance of the downstream VideoQA assistant. (right) VideoQA accuracy results of state-of-the-art VideoQA assistants (Aria and GPT-4o) when equipped with GenS sampler on the LongVideoBench (Vision-Centric subset).
As shown in Figure 1 (right), by selecting more relevant visual frames, GenS significantly enhances the performance of VideoQA Assistants including Aria and GPT-4o. Compared to uniform sampling, GenS improves VideoQA model Aria's accuracy by 13.4 points (with ≤64 frames) and GPT-4o's accuracy by 13.6 points (with ≤40 frames) on the LongVideoBench (v-centric). These substantial improvements highlight that efficient long video perception is a critical bottleneck for modern VideoQA Assistants, and GenS provides a practical solution to unlock their full potential.
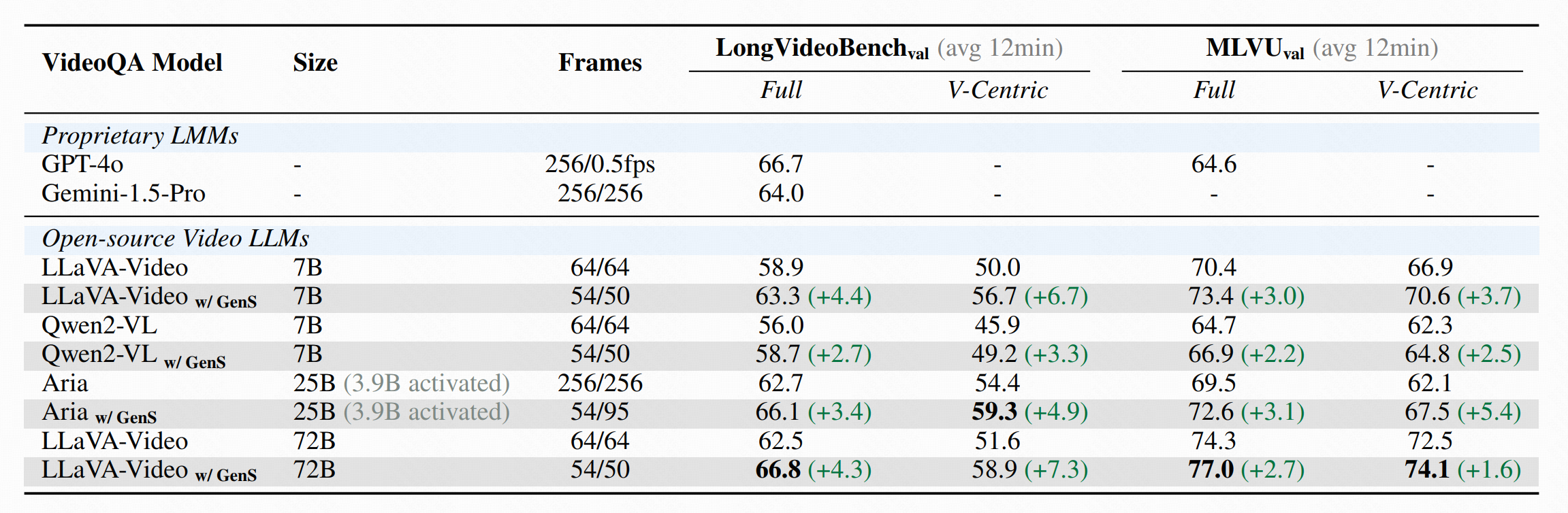
Table 1: Integrating GenS with different VideoQA assistants on LongVideoBench and MLVU benchmarks. Frames N/M indicates input N/M frames for downstream VideoQA models on LongVideoBench and MLVU respectively. Using GenS, we select the K most relevant frames (K <= max frame number of VideoQA models) and report the average number of input frames.
Extensive experiments (Table 1 and Table 2) demonstrate that GenS consistently boosts the performance of various VideoQA models, including open-source models (Qwen2-VL-7B, Aria-25B, VILA-40B, LLaVA-Video-7B/72B) and proprietary assistants (GPT-4o, Gemini1.5-pro). When equipped with GenS, open-source video language models achieve impressive state-of-the-art results on long-form video benchmarks: LLaVA-Video-72B reaches 66.8 on LongVideoBench and 77.0 on MLVU, while Aria obtains 39.2 on HourVideo, surpassing Gemini-1.5-pro by 1.9 points.
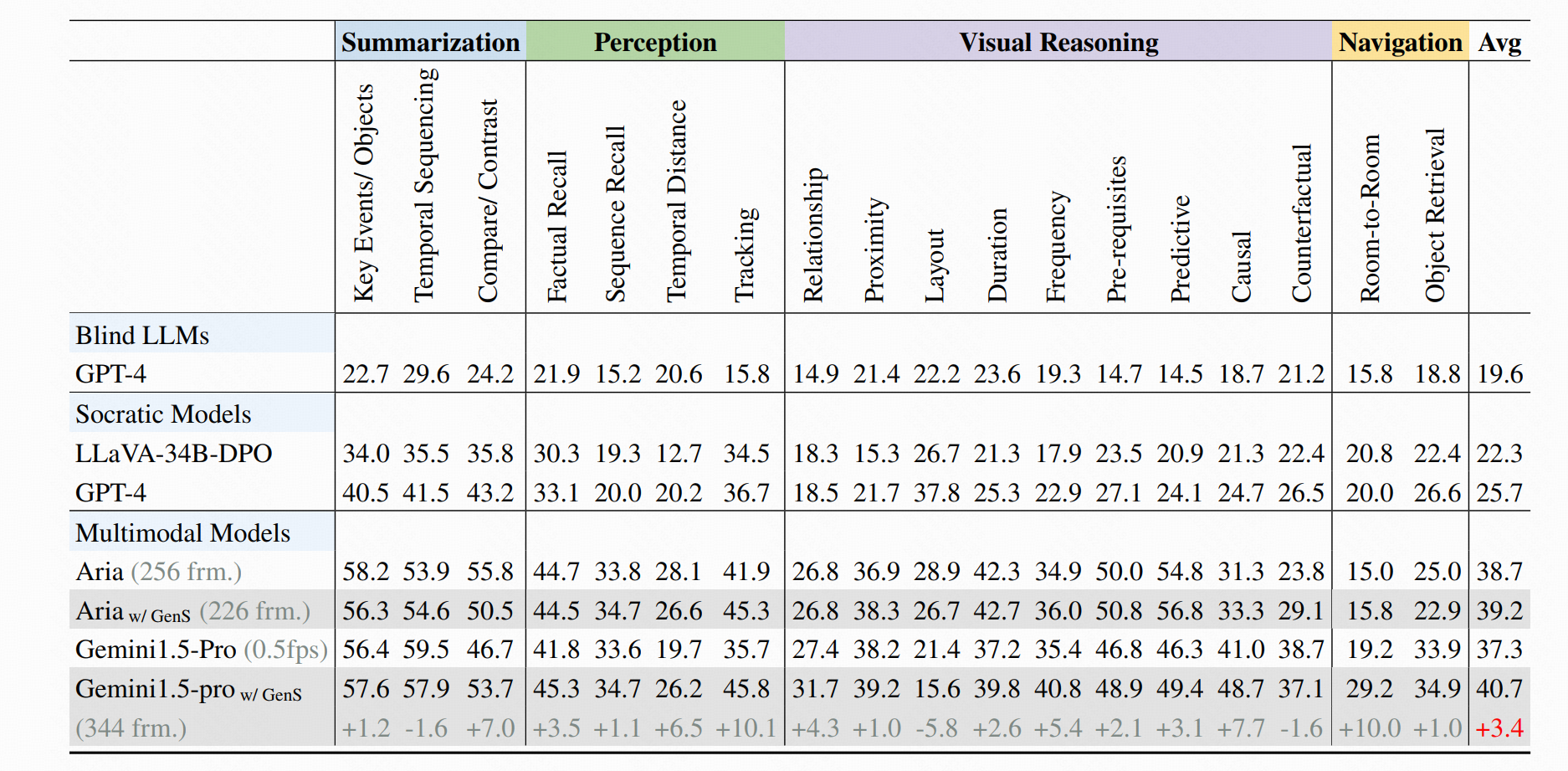
Table 2: Results on HourVideo benchmark, an extremely challenging video dataset with an average duration of 45.7 minutes, containing 113 videos longer than 60 minutes.
Technical Innovations of GenS
-
✨ Temporal Understanding:
GenS effectively captures temporal relationships between successive frames, enabling complex reasoning about temporal sequences such as "immediately after" events in videos.
-
📝 Complex Instruction Understanding:
Powered by built-in LLMs, GenS comprehends complex and flexible textual instructions, allowing it to interpret nuanced queries and identify the most relevant visual content.
-
⚡ Effective Video-Text Alignment:
Its native multi-modal architecture enables sophisticated multi-hop reasoning by seamlessly aligning long-range temporal cues with language semantics, resulting in more accurate frame selection.
GenS is built upon advanced long-context VideoLLMs (such as Aria and Qwen2.5VL), transforming key frame sampling into a generative task. Unlike CLIP-based frame samplers, GenS harnesses the inherent multi-modal capabilities of foundational VideoLLMs and introduces three key innovations:
GenS-Video-150K Dataset
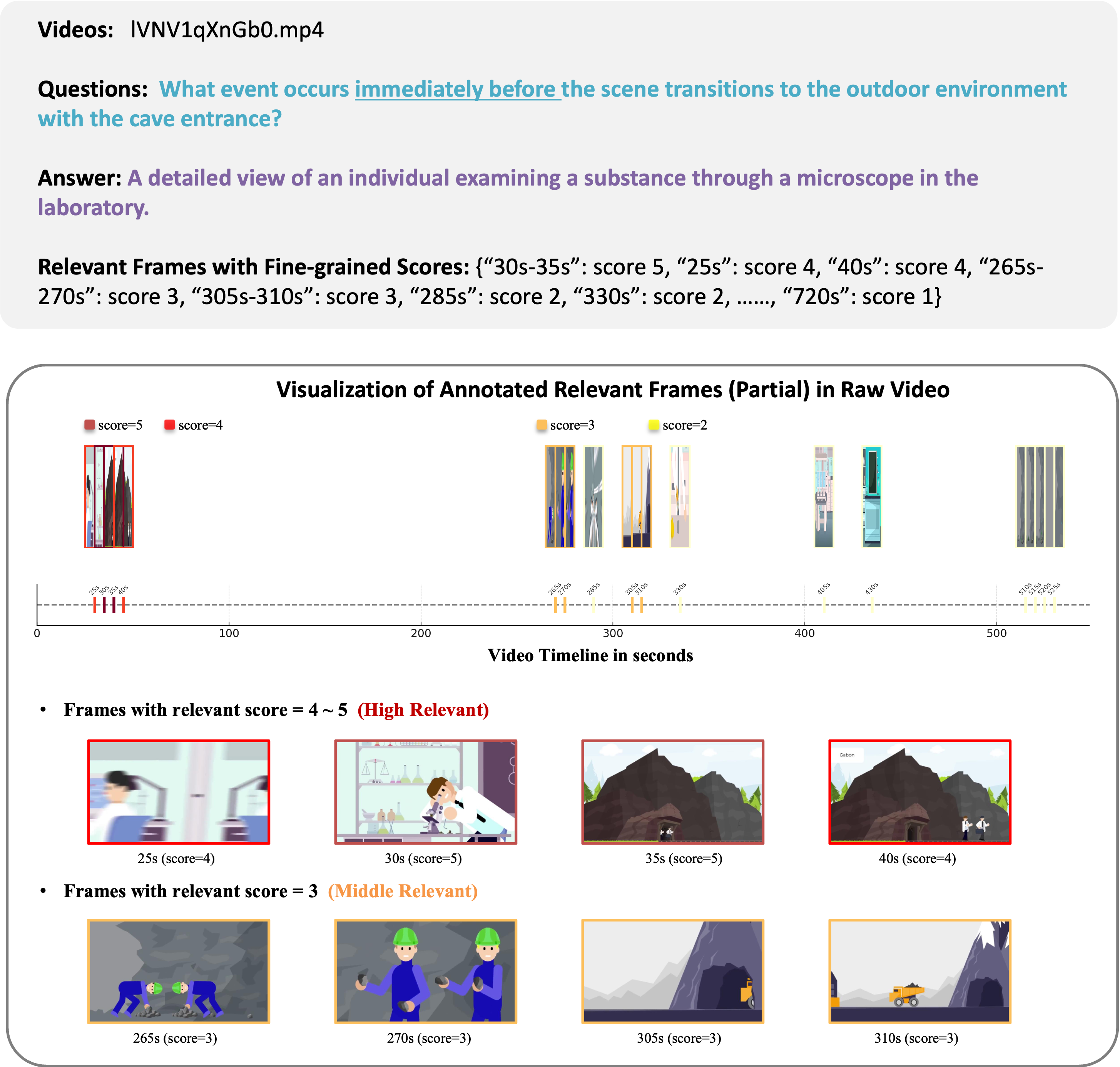
To enable effective frame sampling, we introduce GenS-Video-150K, a large-scale synthetic dataset specifically designed for training frame sampling models. Annotated by GPT-4o, this dataset has two key characteristics: 1) Dense coverage: it annotates approximately 20% of all frames with relevance scores relative to specific questions. 2) Fine-grained assessment with specific confidence scores (level 1 to 5) assigned to each relevant frame, providing detailed distinction of different frames.
Data Statistics:
- Format: {video, question, answer, scored relevant frames}
- #Total Samples: 150K
- Avg Video Duration: 647.5 seconds (~10.8 minutes)
- #QA Task Number: 12
- Relevant Frame Rate: ~20%
- Relevant Scores: 0-5 (0 is non-relevant, 5 is most relevant)
We visualize an annotation example from GenS-Video-150K dataset. For each video-question pair, we annotate frames with fine-grained relevance scores from 0 (irrelevant) to 5 (highly relevant).